在 windows 安裝 Spark Standalone
把 Spark 安裝在 Windows 上,是一種非主流的作法,也不太建議用在正式環境上。不過有時就是想要建立一個小型的 Spark cluster,來進行開發及測試又不想花時間安裝 VM,這時就會想如果能在 Windows 運行那該有多好。
當然,除了自己一步一腳印的自行安裝外,還有另一個簡單的作法是使用 Docker,不過我還是喜歡自己動手去研究每個細節的踏實感。
部署前的準備
Cluster 主機的規劃
先準備三台 windows 的主機,其中有一台是同時運行 master 和 work, 其規劃如下
| 主機名稱 | IP | 說明 |
|---|---|---|
| master | 192.168.10.1 | 同時運行 master 及 worker |
| worker01 | 192.168.10.2 | 運行 worker |
| worker02 | 192.168.10.3 | 運行 worker |
設定 hosts
在 windows 中, hosts 檔案是放在 C:\Windows\System32\drivers\etc 之下。
修改 hosts, 如果 hosts 不存在則新增一個並複製到每一台主機上。
1
2
3192.168.10.1 master
192.168.10.2 worker01
192.168.10.3 worker02
開始部署
安裝所需軟體
我們要部署的版本是 2.2。在部署之前,依照官方網站的需求,要先安裝這些軟體在每一台主機上。
- Java 8
- Scala 2.11.x (如果你不會用到,可以不用裝)
- Python 2.7/3.4 或之後的版本 (如果你不會用到,可以不用裝)
安裝 Spark
- 從 Spark 的官方網站下載,預先編譯好的版本,在這我們選擇 spark-2.2.0-bin-hadoop2.7.tgz。
- 下載完成後,我們使用解壓縮軟體,把它解開到你所想要放的位置。在這裡我們把它解壓縮到 D 磁碟下,並且改名為
spark。
到這裡,就完成的主要安裝。 理論上,Spark 是運行在 JVM 上,應該是可以直接執行。不過在 windows 上,仍是需要一些 hadoop 的輔助程式。到 winutils 下載,選擇 spark 所支援的 Hadoop 版本。
我們選擇 hadoop-2.7.1,在 bin 之下找到 winutils.exe ,把它下載下來並且放到 spark 目錄下的 bin。
設定環境變數
在安裝完後,需要設定環境變數,可以從 控制台 -> 系統 -> 進階系統設定 -> 進階 -> 環境變數 中進行設定。
以下是我們需要設定的環境變數
| 環境變數 | 內容值 | 說明 |
|---|---|---|
| JAVA_HOME | Java 的安裝目錄 | 設定 JAVA 的家目錄 |
| CLASSPATH | %JAVA_HOME%\lib | 設定 JAVA 的類別路徑 |
| SPARK_HOME | SPARK 的安裝目錄 | 設定 SPARK 的家目錄 |
| HADOOP_HOME | SPARK 的安裝目錄 | 設定 HADOOP 的家目錄 |
修改環境變數 PATH ,將以下這些字串附加在 PATH 之後。
1
%JAVA_HOME%\bin;%SPARK_HOME%\bin;%SPARK_HOME%\sbin;%HADOOP_HOME%\bin
啟動 Spark
Master
在命令列模式下,執行以下指令,來啟動 Spark Master:
1
spark-class.cmd org.apache.spark.deploy.master.Master
Worker
在命令列模式下,執行以下指令,來啟動 Spark Worker:
1
spark-class2.cmd org.apache.spark.deploy.worker.Worker spark://master:7077
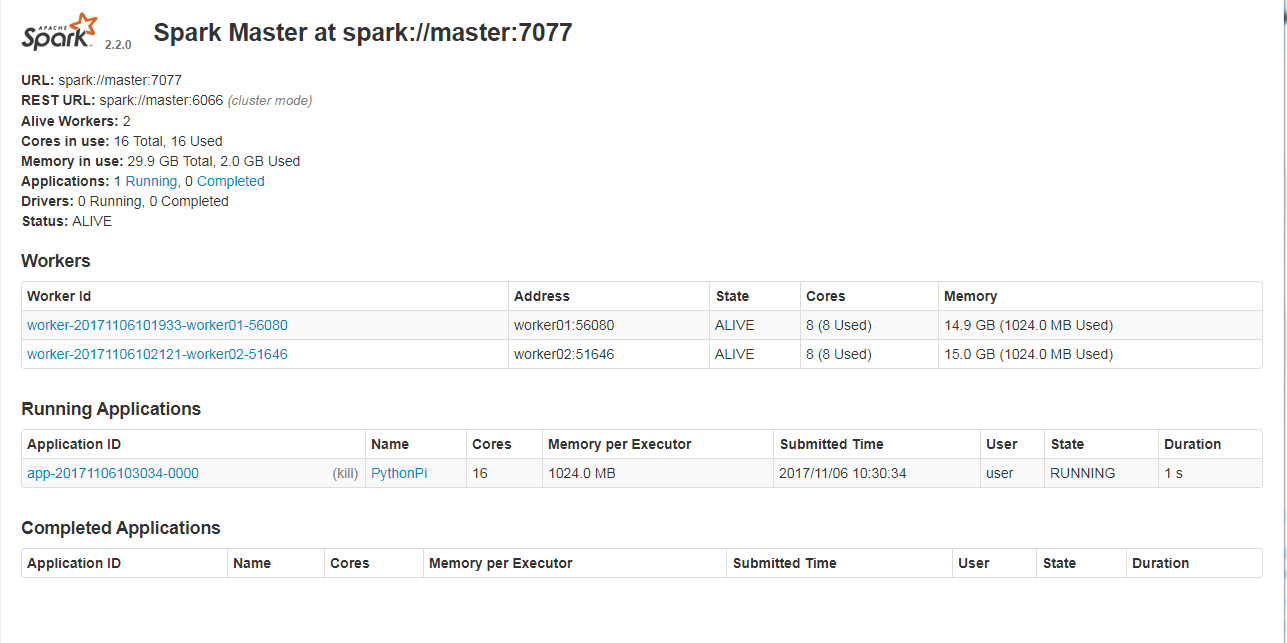
檢視 WebUI
在瀏覽器上鍵入 http://master:8080 ,就可以看到 WebUI。上面會顯示目前 Spark Master 及 Worker 的情況。

驗證
我們使用 Spark 附的範例程式 SparkPi 來驗證 Spark 是否可以正常運行。
首先,先打開命令列模式,並且切換目錄到 SPARK_HOME 之下,執行以下指令,你可以選擇是要執行 Java 版本或是 Python 版本
Java 版本
1
spark-submit —class org.apache.spark.examples.SparkPi —master spark://master:7077 examples/jars/spark-examples_2.11-2.2.0.jar 100
Python 版本
1
spark-submit --master spark://master:7077 examples/src/main/python/pi.py 100
接著打開 WebUI,就可以看到 SparkPi 的運行情況。
曾經踩過的坑
出現 /tmp/hive on HDFS should be writable. Current permissions are: 之類的訊息
這個是指在 HDFS 文件系統下,Spark 沒有寫入
/tmp/hive的權限,解決方式可以用以下指令來改變目錄的權限:
另外還有一種可能,是 Windows 的使用者,沒有足夠的權限。可以檢查此目錄的安全性,把Administrators及使用者設為完全控制。