在 windows 安裝 Spark on Yarn
自從在 windows 安裝 Spark Standalone 之後。就開始有把 Spark on Yarn 也安裝在 Windows 上的念頭? 於是在工作閒暇之餘,開始這次的踩雷之旅。
部署前的準備
Cluster 主機的規劃
先準備三台 windows 的主機,其規劃如下:
| 主機名稱 | IP | 說明 |
|---|---|---|
| master | 192.168.10.1 | 運行 name node, resource manager |
| slave01 | 192.168.10.2 | 運行 node manager, data node |
| slave02 | 192.168.10.3 | 運行 node manager, data node |
設定 hosts
在 windows 中, hosts 檔案是放在 C:\Windows\System32\drivers\etc 之下。
修改 hosts,如果 hosts 不存在則新增一個並複製到每一台主機上。
1
2
3192.168.10.1 master
192.168.10.2 slave01
192.168.10.3 slave02
開始部署
安裝所需軟體
我們要部署的版本是 Spark 2.2。在部署之前,依照官方網站的需求,要先安裝這些軟體在每一台主機上。
- Java 8
- Scala 2.11.x (如果你不會用到,可以不用裝)
- Python 2.7/3.4 或之後的版本 (如果你不會用到,可以不用裝)
<a name="install_hodoop"></a > 安裝 Hadoop
- 從 Hadoop 的官方網站下載,預先編譯好的版本,
在這我們選擇 hadoop-2.7.4.tgz。 - 下載完成後,我們使用解壓縮軟體,把它解開到你所想要放的位置。在這裡我們把它解壓縮到 D 磁碟下,並且改名為
hadoop。
在 windows 下,還需要編譯 hadoop 的原始碼來產生 dll 檔及 exe 檔。所幸,已經有神人幫我們編譯好,連到 winutils,選擇 hadoop-2.7.1 目錄下的 bin。把全部的檔案都下載下來,並且放到 hadoop 目錄下的 bin。
安裝 Spark
- 從 Spark 的官方網站下載,預先編譯好的版本,
在這我們選擇 spark-2.2.0-bin-hadoop2.7.tgz。 - 下載完成後,我們使用解壓縮軟體,把它解開到你所想要放的位置。在這裡我們把它解壓縮到 D 磁碟下,並且改名為
spark。
設定環境變數
在安裝完後,需要設定環境變數,可以從 控制台 -> 系統 -> 進階系統設定 -> 進階 -> 環境變數 中進行設定.
以下是我們需要設定的環境變數
| 環境變數 | 內容值 | 說明 |
|---|---|---|
| JAVA_HOME | Java 的安裝目錄 | 設定 JAVA 的家目錄 |
| CLASSPATH | %JAVA_HOME%\lib | 設定 JAVA 的類別路徑 |
| SPARK_HOME | SPARK 的安裝目錄 | 設定 SPARK 的家目錄 |
| HADOOP_HOME | HADOOP 的安裝目錄 | 設定 HADOOP 的家目錄 |
| HADOOP_CONF_HOME | %HADOOP_HOME%/etc/hadoop | 設定 HADOOP 的設定檔目錄 |
| YARN_CONF_HOME | %HADOOP_HOME%/etc/hadoop | 設定 YARN 的設定檔目錄 |
接著將這些值附加在 PATH 之後
1
%JAVA_HOME%\bin;%SPARK_HOME%\bin;%SPARK_HOME%\sbin;%HADOOP_HOME%\bin
設定 Hadoop
到 %HADOOP_HOME%/etc/hadoop 目錄來進行設定,總共有以下 5 個文件需要設定:
設定 slave 的 host 或 IP
1
2slave01
slave02
設定 core-site.xml
1
2
3
4
5
6
7
8
9
10
11<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000/</value>
</property>
<!— 設定 hadoop 的暫存目錄—>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/D:/workspaces/hadoop</value>
</property>
</configuration>
設定 hdfs-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<!— 設定 hadoop name node 的工作目錄—>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/D:/workspaces/hadoop/dfs/name</value>
</property>
<!— 設定 hadoop data node 的工作目錄—>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/D:/workspaces/hadoop/dfs/data</value>
</property>
<!— 預設值為3,因為我們只有2台slave 主機,故設為2—>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
設定 mapred-site.xml
1
2
3
4
5
6<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
設定 yarn-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8035</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
最後再把設定檔同步到其它台機器。
啟動 Hadoop
Master
如果是第一次執行,需要先做 name node 的格式化
1
hadoop namenode -format
再編輯 %HADOOP_HOME%\sbin\start-dfs.cmd ,把啟動 data node 的指令註解起來。
1
2start "Apache Hadoop Distribution" hadoop namenode
rem start "Apache Hadoop Distribution" hadoop datanode
接著再編輯 %HADOOP_HOME%\sbin\start-yarn.cmd ,把啟動 node manager 的指令註解起來.
1
2start "Apache Hadoop Distribution" yarn resourcemanager
rem start "Apache Hadoop Distribution" yarn nodemanager
編輯完後, 再以系統管理員身分執行來執行這二個檔。
可以使用 jps 指令來查看啟動的程序,正常的話,會有以下這些程序。
1
2
310024 ResourceManager
13304 NameNode
3212 Jps
Slave
編輯 %HADOOP_HOME%\sbin\start-dfs.cmd ,把啟動 name node 的指令註解起來。
1
2rem start "Apache Hadoop Distribution" hadoop namenode
start "Apache Hadoop Distribution" hadoop datanode
接著再編輯 %HADOOP_HOME%\sbin\start-yarn.cmd ,把啟動 resource manager 的指令註解起來。
1
2rem start "Apache Hadoop Distribution" yarn resourcemanager
start "Apache Hadoop Distribution" yarn nodemanager
編輯完後, 以 系統管理員身分執行 來執行這二個檔。
可以使用 jps 指令來查看啟動的程序, 正常的話, 會有以下這些程序。
1
2
310024 ResourceManager
15372 NodeManager
15392 Jps
檢視 WebUI
在瀏覽器上鍵入 http://master:8088/cluster/nodes ,就可以看到 WebUI。上面會顯示目前 Hadoop Cluster 的情況。
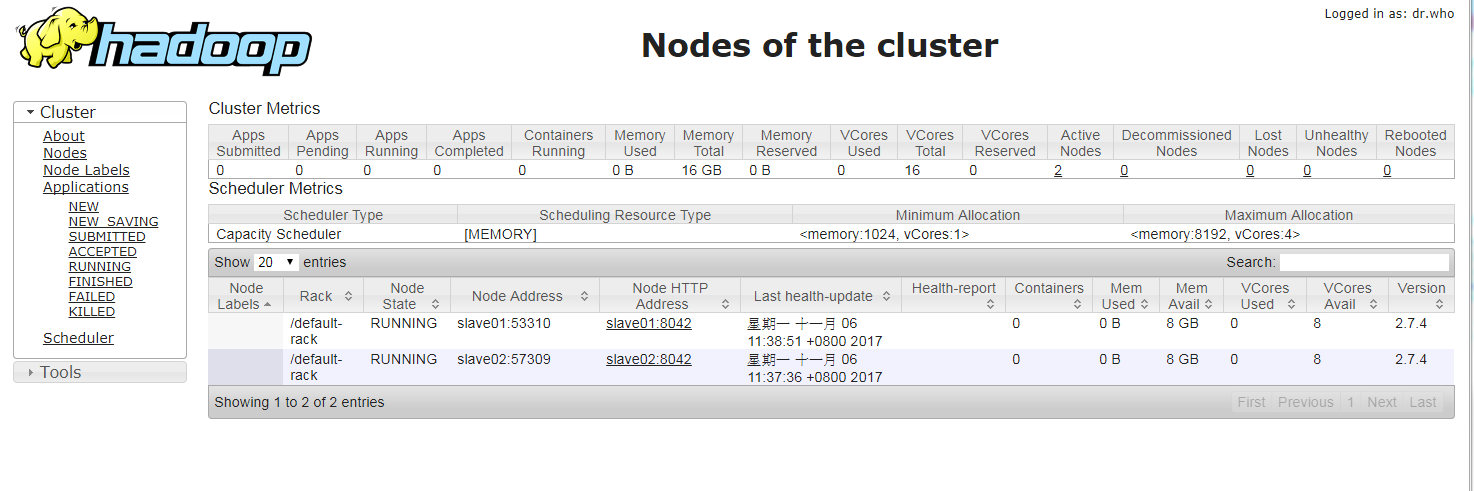
驗證
在 YARN 模式下,有二種運行模式 yarn-client 及 yarn-cluster。
有關它們的區別可以參考 Spark:Yarn-cluster 和 Yarn-client 区别与联系
我們使用 Spark 附的範例程式 SparkPi 來驗證是否可以正常運行。到 SPARK_HOME 之下,執行以下指令,你可以選擇是要執行 Java 版本或是 Python 版本。
Java 版本
1
2
3
4# yarn-client 模式
spark-submit —class org.apache.spark.examples.SparkPi —master yarn-client examples/jars/spark-examples_2.11-2.2.0.jar 100
# yarn-cluster 模式
spark-submit —class org.apache.spark.examples.SparkPi —master yarn-cluster examples/jars/spark-examples_2.11-2.2.0.jar 100
Python 版本
1
2
3
4# yarn-client 模式
spark-submit --master yarn-client examples/src/main/python/pi.py 100
# yarn-cluster 模式
spark-submit --master yarn-cluster examples/src/main/python/pi.py 100
接著打開 WebUI, 鍵入 http://master:8088/cluster/apps 就可以看到運行結果。
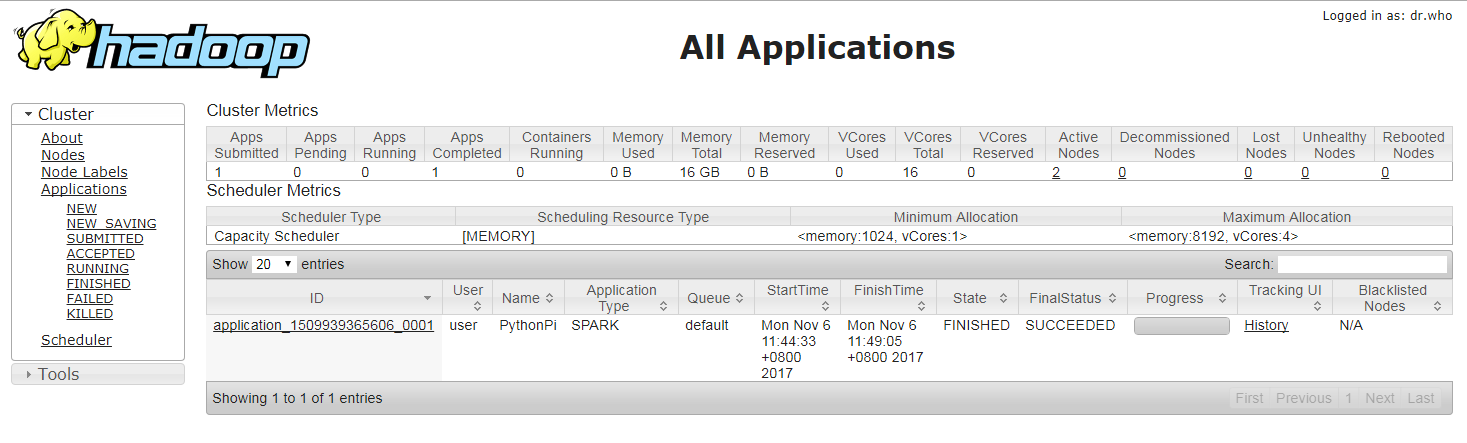
曾經踩過的坑
出現 xxxxx on HDFS should be writable. 的訊息
這個是指在 HDFS 文件系統下,沒有寫入目錄的權限,解決方式可以用以下指令來改變目錄的權限:
1
winutils chmod 766 -R <目錄名稱>
系統無法找到指定的批次標籤 - resourcemanager
可能是批次檔的行結尾字元不正確,可以檢查行結尾字元是否為 windows 格式: <CR><LF>
出現 doesn't satisfy minimum allocations 的訊息
這是指所分配的資源不足, 或是不符合最小需求。可以在 yarn-site.xml 中修改資源設定。
1
2
3
4
5
6
7
8
9
10
11
12<!-- 分配記憶體資源, 至少要大於 1024 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
<!-- 分配CPU的核心資源, 通常是CPU的核心數-->
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>8</value>
</property>
出現 Datanode denied communication with namenode because hostname cannot be resolved 訊息
這是因為 DNS 反解析不正確所造成的。你可以在 hdfs-site.xml 中關掉 DNS 反查。
1
2
3
4<property>
<name>dfs.namenode.datanode.registration.ip-hostname-check</name>
<value>false</value>
</property>
出現 java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO 訊息
找不到或是缺少相關的 DLL 檔。可以參照 安裝 Hadoop, 安裝相關的 DLL 檔。